Since I migrated from Pleroma to Akkoma the service crashes from time to time. Maybe I can relate this to times with a high number of incoming http requests.
Syslog tells me:
2023-09-24T21:19:47.503499+02:00 akkoma pleroma[731]: eheap_alloc: Cannot allocate 2545496 bytes of memory (of type "heap").
2023-09-24T21:19:47.507901+02:00 akkoma kernel: [27861.806148] __vm_enough_memory: pid: 770, comm: 1_dirty_cpu_sch, no enough memory for the allocation
2023-09-24T21:19:47.507916+02:00 akkoma kernel: [27861.806159] __vm_enough_memory: pid: 770, comm: 1_dirty_cpu_sch, no enough memory for the allocation
2023-09-24T21:19:47.507918+02:00 akkoma kernel: [27861.806164] __vm_enough_memory: pid: 770, comm: 1_dirty_cpu_sch, no enough memory for the allocation
2023-09-24T21:19:47.507919+02:00 akkoma kernel: [27861.806206] __vm_enough_memory: pid: 770, comm: 1_dirty_cpu_sch, no enough memory for the allocation
2023-09-24T21:19:47.507920+02:00 akkoma kernel: [27861.806215] __vm_enough_memory: pid: 770, comm: 1_dirty_cpu_sch, no enough memory for the allocation
2023-09-24T21:19:47.507921+02:00 akkoma kernel: [27861.806219] __vm_enough_memory: pid: 770, comm: 1_dirty_cpu_sch, no enough memory for the allocation
2023-09-24T21:19:47.507923+02:00 akkoma kernel: [27861.806221] __vm_enough_memory: pid: 770, comm: 1_dirty_cpu_sch, no enough memory for the allocation
2023-09-24T21:19:47.507924+02:00 akkoma kernel: [27861.806529] __vm_enough_memory: pid: 770, comm: 1_dirty_cpu_sch, no enough memory for the allocation
2023-09-24T21:19:47.507925+02:00 akkoma kernel: [27861.806532] __vm_enough_memory: pid: 770, comm: 1_dirty_cpu_sch, no enough memory for the allocation
2023-09-24T21:19:47.507926+02:00 akkoma kernel: [27861.806555] __vm_enough_memory: pid: 770, comm: 1_dirty_cpu_sch, no enough memory for the allocation
2023-09-24T21:19:47.598950+02:00 akkoma pleroma[731]: #015
2023-09-24T21:19:49.347455+02:00 akkoma systemd[1]: pleroma.service: Main process exited, code=exited, status=1/FAILURE
2023-09-24T21:19:49.347482+02:00 akkoma systemd[1]: pleroma.service: Failed with result 'exit-code'.
2023-09-24T21:19:49.347498+02:00 akkoma systemd[1]: pleroma.service: Unit process 764 (epmd) remains running after unit stopped.
2023-09-24T21:19:49.347513+02:00 akkoma systemd[1]: pleroma.service: Consumed 12min 43.779s CPU time.
2023-09-24T21:19:49.481436+02:00 akkoma systemd[1]: pleroma.service: Scheduled restart job, restart counter is at 1.
2023-09-24T21:19:49.483249+02:00 akkoma systemd[1]: Stopped pleroma.service - Pleroma social network.
2023-09-24T21:19:49.483568+02:00 akkoma systemd[1]: pleroma.service: Consumed 12min 43.779s CPU time.
2023-09-24T21:19:49.483974+02:00 akkoma systemd[1]: pleroma.service: Found left-over process 764 (epmd) in control group while starting unit. Ignoring.
2023-09-24T21:19:49.484092+02:00 akkoma systemd[1]: This usually indicates unclean termination of a previous run, or service implementation deficiencies.
2023-09-24T21:19:49.497963+02:00 akkoma systemd[1]: Started pleroma.service - Pleroma social network.
Sometimes its not type “heap” but type “old_heap”.
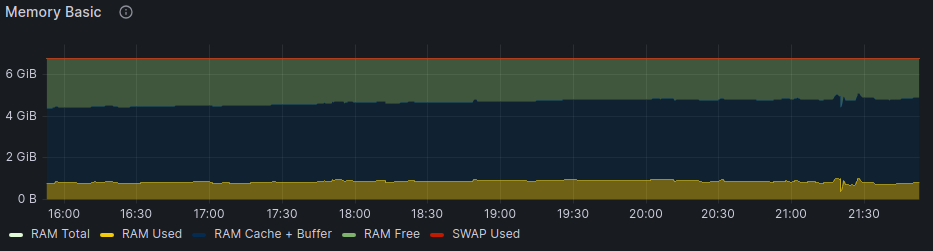
And here is the memory utilization during the last crash and a few hours of historic data:
I already increased the virtual machines memory by 1 GB.
This never happened during the last two and a half years with Pleroma. If someone can convince me that erl_crash.dump does not contain sensitive information I would be happy to share.
I completely forgot the system specs. 
Setup type: OTP
OS: Debian 12
PostgreSQL: 15.3
Akkoma version: 3.10.4-0-gebfb617
CPU: 1 vCPU
RAM: 7 GB (6 GB while running Pleroma)
The instance was migrated from Pleroma 2.5.5 to Akkoma 3.10.4-0-gebfb617 (2023.08 stable?). The system itself was not changed.
my pointer would be to look into how much memory postgres is using (and reserving) - postgres can easily eat that much memory, and naturally it increases as a function of time which means you’d have probably hit this problem no matter what you were running
Thanks for your fast reply.  I jumped in the same direction and found this:
I jumped in the same direction and found this:
Nearly every time eheap_alloc happens I can find the statement SELECT distinct split_part(u0."nickname", '@', 2) FROM "users" AS u0 WHERE (u0."local" != $1) in the PostgreSQL log.
2023-09-22 / 14:18
Syslog:
2023-09-22T14:18:32.403555+02:00 akkoma pleroma[155547]: eheap_alloc: Cannot allocate 28654824 bytes of memory (of type "heap").
PostgreSQL:
2023-09-22 14:18:32.439 CEST [180231] pleroma@pleroma LOG: unexpected EOF on client connection with an open transaction
2023-09-22 14:18:46.064 CEST [181326] pleroma@pleroma ERROR: canceling statement due to user request
2023-09-22 14:18:46.064 CEST [181326] pleroma@pleroma STATEMENT: SELECT distinct split_part(u0."nickname", '@', 2) FROM "users" AS u0 WHERE (u0."local" != $1)
2023-09-22 14:18:46.064 CEST [181326] pleroma@pleroma LOG: could not send data to client: Broken pipe
2023-09-22 14:18:46.064 CEST [181326] pleroma@pleroma FATAL: connection to client lost
2023-09-24 / 21:19
Syslog:
2023-09-24T21:19:47.503499+02:00 akkoma pleroma[731]: eheap_alloc: Cannot allocate 2545496 bytes of memory (of type "heap")
PostgreSQL:
2023-09-24 21:19:47.565 CEST [3310] pleroma@pleroma LOG: unexpected EOF on client connection with an open transaction
2023-09-24 21:19:57.813 CEST [17010] pleroma@pleroma ERROR: canceling statement due to user request
2023-09-24 21:19:57.813 CEST [17010] pleroma@pleroma STATEMENT: SELECT distinct split_part(u0."nickname", '@', 2) FROM "users" AS u0 WHERE (u0."local" != $1)
2023-09-24 21:19:57.814 CEST [17010] pleroma@pleroma LOG: could not send data to client: Broken pipe
2023-09-24 21:19:57.814 CEST [17010] pleroma@pleroma FATAL: connection to client lost
What I don’t understand here is the memory consumption. The DB was 8 GB in size with Pleroma and is now only 2,5 GB (after running -–prune-orphaned-activities) with Akkoma. However, I will stick to the PostgreSQL’s memory consumption. That sounds promising.
bear in mind that on-disk DB dump space will not be the same as in-memory space, since indices are massive
One year of playing around with the resources of my Akkoma virtual machine. 
In the meantime I moved the Database to a dedicated server and increased the memory of the Akkoma server to 8 GB. This 8 GB are now dedicated to Akkoma (and Debian of course). The Akkoma process still crashes from time to time. Yesterday after an account with 8.7k followers boosted one of my toots. Maybe 8 GB memory is to less in such a case but it still doesn’t feel right.
yeah that happens from time to time, the DDoS from people like gargron retweeting you is sadly an unavoidable consequence of the network being… a network
you can mitigate it somewhat with caches (varnish etc) but a DDoS it remains
I have solved the problem for myself. Even if I can’t really understand why the solution works. Maybe it is helpful for someone:
Akkoma was migrated from a VM with Debian 12 and 8 GB RAM to an LXC container with Debian 12 and 2 GB RAM. Akkoma has now been running stable for four months. Both the VM and the LXC container are/were running on the same Proxmox server.
1 Like